Deep learning examples¶
![]()
This notebooks contains examples with neural network models.
Table of Contents
[1]:
import torch
import random
import pandas as pd
import numpy as np
from etna.datasets.tsdataset import TSDataset
from etna.pipeline import Pipeline
from etna.transforms import DateFlagsTransform
from etna.transforms import LagTransform
from etna.transforms import LinearTrendTransform
from etna.metrics import SMAPE, MAPE, MAE
from etna.analysis import plot_backtest
from etna.models import SeasonalMovingAverageModel
import warnings
warnings.filterwarnings("ignore")
/Users/marti/Library/Caches/pypoetry/virtualenvs/etna-LkP65DRT-py3.9/lib/python3.9/site-packages/pandas/compat/__init__.py:124: UserWarning: Could not import the lzma module. Your installed Python is incomplete. Attempting to use lzma compression will result in a RuntimeError.
warnings.warn(msg)
/Users/marti/Library/Caches/pypoetry/virtualenvs/etna-LkP65DRT-py3.9/lib/python3.9/site-packages/torchmetrics/utilities/prints.py:36: UserWarning: Torchmetrics v0.9 introduced a new argument class property called `full_state_update` that has
not been set for this class (SMAPE). The property determines if `update` by
default needs access to the full metric state. If this is not the case, significant speedups can be
achieved and we recommend setting this to `False`.
We provide an checking function
`from torchmetrics.utilities import check_forward_no_full_state`
that can be used to check if the `full_state_update=True` (old and potential slower behaviour,
default for now) or if `full_state_update=False` can be used safely.
warnings.warn(*args, **kwargs)
1. Creating TSDataset¶
We are going to take transformed [Household Electric Power Consumption] dataset. Let’s load and look at it.
[2]:
original_df = pd.read_csv("data/example_dataset.csv")
original_df.head()
[2]:
| timestamp | segment | target | |
|---|---|---|---|
| 0 | 2019-01-01 | segment_a | 170 |
| 1 | 2019-01-02 | segment_a | 243 |
| 2 | 2019-01-03 | segment_a | 267 |
| 3 | 2019-01-04 | segment_a | 287 |
| 4 | 2019-01-05 | segment_a | 279 |
Our library works with the spacial data structure TSDataset. Let’s create it as it was done in “Get started” notebook.
[3]:
df = TSDataset.to_dataset(original_df)
ts = TSDataset(df, freq="D")
ts.head(5)
[3]:
| segment | segment_a | segment_b | segment_c | segment_d |
|---|---|---|---|---|
| feature | target | target | target | target |
| timestamp | ||||
| 2019-01-01 | 170 | 102 | 92 | 238 |
| 2019-01-02 | 243 | 123 | 107 | 358 |
| 2019-01-03 | 267 | 130 | 103 | 366 |
| 2019-01-04 | 287 | 138 | 103 | 385 |
| 2019-01-05 | 279 | 137 | 104 | 384 |
2. Architecture¶
Our library uses PyTorch Forecasting to work with time series neural networks. To include it in our current architecture we use PytorchForecastingTransform class.
Let’s look at it closer.
[4]:
from etna.transforms import PytorchForecastingTransform
[5]:
?PytorchForecastingTransform
Init signature:
PytorchForecastingTransform(
max_encoder_length: int = 30,
min_encoder_length: Optional[int] = None,
min_prediction_idx: Optional[int] = None,
min_prediction_length: Optional[int] = None,
max_prediction_length: int = 1,
static_categoricals: Optional[List[str]] = None,
static_reals: Optional[List[str]] = None,
time_varying_known_categoricals: Optional[List[str]] = None,
time_varying_known_reals: Optional[List[str]] = None,
time_varying_unknown_categoricals: Optional[List[str]] = None,
time_varying_unknown_reals: Optional[List[str]] = None,
variable_groups: Optional[Dict[str, List[int]]] = None,
constant_fill_strategy: Optional[Dict[str, Union[str, float, int, bool]]] = None,
allow_missing_timesteps: bool = True,
lags: Optional[Dict[str, List[int]]] = None,
add_relative_time_idx: bool = True,
add_target_scales: bool = True,
add_encoder_length: Union[bool, str] = True,
target_normalizer: Union[pytorch_forecasting.data.encoders.TorchNormalizer, pytorch_forecasting.data.encoders.NaNLabelEncoder, pytorch_forecasting.data.encoders.EncoderNormalizer, str, List[Union[pytorch_forecasting.data.encoders.TorchNormalizer, pytorch_forecasting.data.encoders.NaNLabelEncoder, pytorch_forecasting.data.encoders.EncoderNormalizer]], Tuple[Union[pytorch_forecasting.data.encoders.TorchNormalizer, pytorch_forecasting.data.encoders.NaNLabelEncoder, pytorch_forecasting.data.encoders.EncoderNormalizer]]] = 'auto',
categorical_encoders: Optional[Dict[str, pytorch_forecasting.data.encoders.NaNLabelEncoder]] = None,
scalers: Optional[Dict[str, Union[sklearn.preprocessing._data.StandardScaler, sklearn.preprocessing._data.RobustScaler, pytorch_forecasting.data.encoders.TorchNormalizer, pytorch_forecasting.data.encoders.EncoderNormalizer]]] = None,
)
Docstring:
Transform for models from PytorchForecasting library.
Notes
-----
This transform should be added at the very end of ``transforms`` parameter.
Init docstring:
Init transform.
Parameters here is used for initialization of :py:class:`pytorch_forecasting.data.timeseries.TimeSeriesDataSet` object.
File: ~/Projects/etna/etna/transforms/nn/pytorch_forecasting.py
Type: ABCMeta
Subclasses:
"""
Init signature:
PytorchForecastingTransform(
max_encoder_length: int = 30,
min_encoder_length: int = None,
min_prediction_idx: int = None,
min_prediction_length: int = None,
max_prediction_length: int = 1,
static_categoricals: List[str] = [],
static_reals: List[str] = [],
time_varying_known_categoricals: List[str] = [],
time_varying_known_reals: List[str] = [],
time_varying_unknown_categoricals: List[str] = [],
time_varying_unknown_reals: List[str] = [],
variable_groups: Dict[str, List[int]] = {},
constant_fill_strategy: Dict[str, Union[str, float, int, bool]] = {},
allow_missing_timesteps: bool = True,
lags: Dict[str, List[int]] = {},
add_relative_time_idx: bool = True,
add_target_scales: bool = True,
add_encoder_length: Union[bool, str] = True,
target_normalizer: Union[pytorch_forecasting.data.encoders.TorchNormalizer, pytorch_forecasting.data.encoders.NaNLabelEncoder, pytorch_forecasting.data.encoders.EncoderNormalizer, str, List[Union[pytorch_forecasting.data.encoders.TorchNormalizer, pytorch_forecasting.data.encoders.NaNLabelEncoder, pytorch_forecasting.data.encoders.EncoderNormalizer]], Tuple[Union[pytorch_forecasting.data.encoders.TorchNormalizer, pytorch_forecasting.data.encoders.NaNLabelEncoder, pytorch_forecasting.data.encoders.EncoderNormalizer]]] = 'auto',
categorical_encoders: Dict[str, pytorch_forecasting.data.encoders.NaNLabelEncoder] = None,
scalers: Dict[str, Union[sklearn.preprocessing._data.StandardScaler, sklearn.preprocessing._data.RobustScaler, pytorch_forecasting.data.encoders.TorchNormalizer, pytorch_forecasting.data.encoders.EncoderNormalizer]] = {},
)
Docstring: Transform for models from PytorchForecasting library.
Init docstring:
Parameters for TimeSeriesDataSet object.
Reference
---------
https://github.com/jdb78/pytorch-forecasting/blob/v0.8.5/pytorch_forecasting/data/timeseries.py#L117
"""
We can see a pretty scary signature, but don’t panic, we will look at the most important parameters.
time_varying_known_reals— known real values that change across the time (real regressors), now it it necessary to add “time_idx” variable to the list;time_varying_unknown_reals— our real value target, set it to["target"];max_prediction_length— our horizon for forecasting;max_encoder_length— length of past context to use;static_categoricals— static categorical values, for example, if we use multiple segments it can be some its characteristics including identifier: “segment”;time_varying_known_categoricals— known categorical values that change across the time (categorical regressors);target_normalizer— class for normalization targets across different segments.
Our library currently supports these models: * DeepAR, * TFT.
3. Testing models¶
In this section we will test our models on example.
3.1 DeepAR¶
Before training let’s fix seeds for reproducibility.
[6]:
torch.manual_seed(42)
random.seed(42)
np.random.seed(42)
Creating transforms for DeepAR.
[7]:
from pytorch_forecasting.data import GroupNormalizer
HORIZON = 7
transform_date = DateFlagsTransform(day_number_in_week=True, day_number_in_month=False, out_column="dateflag")
num_lags = 10
transform_lag = LagTransform(
in_column="target",
lags=[HORIZON + i for i in range(num_lags)],
out_column="target_lag",
)
lag_columns = [f"target_lag_{HORIZON+i}" for i in range(num_lags)]
transform_deepar = PytorchForecastingTransform(
max_encoder_length=HORIZON,
max_prediction_length=HORIZON,
time_varying_known_reals=["time_idx"] + lag_columns,
time_varying_unknown_reals=["target"],
time_varying_known_categoricals=["dateflag_day_number_in_week"],
target_normalizer=GroupNormalizer(groups=["segment"]),
)
Now we are going to start backtest.
[8]:
from etna.models.nn import DeepARModel
model_deepar = DeepARModel(max_epochs=150, learning_rate=[0.01], gpus=0, batch_size=64)
metrics = [SMAPE(), MAPE(), MAE()]
pipeline_deepar = Pipeline(
model=model_deepar,
horizon=HORIZON,
transforms=[transform_lag, transform_date, transform_deepar],
)
[9]:
metrics_deepar, forecast_deepar, fold_info_deepar = pipeline_deepar.backtest(ts, metrics=metrics, n_folds=3, n_jobs=1)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
------------------------------------------------------------------
0 | loss | NormalDistributionLoss | 0
1 | logging_metrics | ModuleList | 0
2 | embeddings | MultiEmbedding | 35
3 | rnn | LSTM | 2.2 K
4 | distribution_projector | Linear | 22
------------------------------------------------------------------
2.3 K Trainable params
0 Non-trainable params
2.3 K Total params
0.009 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 49.2s remaining: 0.0s
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
------------------------------------------------------------------
0 | loss | NormalDistributionLoss | 0
1 | logging_metrics | ModuleList | 0
2 | embeddings | MultiEmbedding | 35
3 | rnn | LSTM | 2.2 K
4 | distribution_projector | Linear | 22
------------------------------------------------------------------
2.3 K Trainable params
0 Non-trainable params
2.3 K Total params
0.009 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 1.7min remaining: 0.0s
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
------------------------------------------------------------------
0 | loss | NormalDistributionLoss | 0
1 | logging_metrics | ModuleList | 0
2 | embeddings | MultiEmbedding | 35
3 | rnn | LSTM | 2.2 K
4 | distribution_projector | Linear | 22
------------------------------------------------------------------
2.3 K Trainable params
0 Non-trainable params
2.3 K Total params
0.009 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 2.6min remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 2.6min finished
Let’s compare results across different segments.
[10]:
metrics_deepar
[10]:
| segment | SMAPE | MAPE | MAE | fold_number | |
|---|---|---|---|---|---|
| 1 | segment_a | 7.814030 | 7.459738 | 40.393367 | 0 |
| 1 | segment_a | 2.920065 | 2.877445 | 15.842054 | 1 |
| 1 | segment_a | 7.900189 | 7.524698 | 42.506675 | 2 |
| 0 | segment_b | 6.273527 | 6.073480 | 15.615147 | 0 |
| 0 | segment_b | 4.650923 | 4.489272 | 11.729819 | 1 |
| 0 | segment_b | 3.321326 | 3.327382 | 7.786591 | 2 |
| 2 | segment_c | 3.465605 | 3.406908 | 5.928295 | 0 |
| 2 | segment_c | 5.709290 | 5.528213 | 10.160812 | 1 |
| 2 | segment_c | 4.395499 | 4.327041 | 7.911625 | 2 |
| 3 | segment_d | 4.286532 | 4.364300 | 35.523185 | 0 |
| 3 | segment_d | 5.246669 | 5.430598 | 42.273751 | 1 |
| 3 | segment_d | 4.618827 | 4.489909 | 39.021101 | 2 |
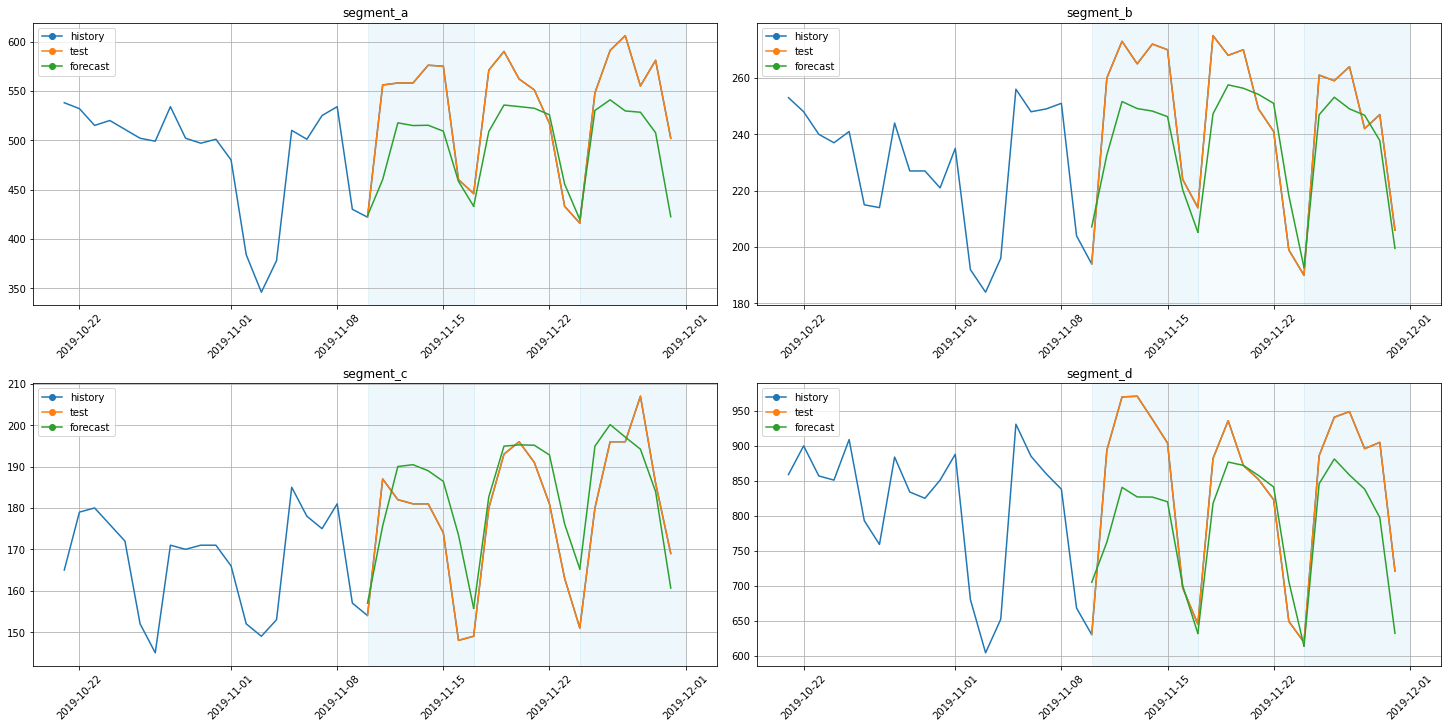
To summarize it we will take mean value of SMAPE metric because it is scale tolerant.
[11]:
score = metrics_deepar["SMAPE"].mean()
print(f"Average SMAPE for DeepAR: {score:.3f}")
Average SMAPE for DeepAR: 5.050
Visualize results.
[12]:
plot_backtest(forecast_deepar, ts, history_len=20)
3.2 TFT¶
Let’s move to the next model.
[13]:
torch.manual_seed(42)
random.seed(42)
np.random.seed(42)
[14]:
transform_date = DateFlagsTransform(day_number_in_week=True, day_number_in_month=False, out_column="dateflag")
num_lags = 10
transform_lag = LagTransform(
in_column="target",
lags=[HORIZON + i for i in range(num_lags)],
out_column="target_lag",
)
lag_columns = [f"target_lag_{HORIZON+i}" for i in range(num_lags)]
transform_tft = PytorchForecastingTransform(
max_encoder_length=HORIZON,
max_prediction_length=HORIZON,
time_varying_known_reals=["time_idx"],
time_varying_unknown_reals=["target"],
time_varying_known_categoricals=["dateflag_day_number_in_week"],
static_categoricals=["segment"],
target_normalizer=GroupNormalizer(groups=["segment"]),
)
[15]:
from etna.models.nn import TFTModel
model_tft = TFTModel(max_epochs=200, learning_rate=[0.01], gpus=0, batch_size=64)
pipeline_tft = Pipeline(
model=model_tft,
horizon=HORIZON,
transforms=[transform_lag, transform_date, transform_tft],
)
[16]:
metrics_tft, forecast_tft, fold_info_tft = pipeline_tft.backtest(ts, metrics=metrics, n_folds=3, n_jobs=1)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
----------------------------------------------------------------------------------------
0 | loss | QuantileLoss | 0
1 | logging_metrics | ModuleList | 0
2 | input_embeddings | MultiEmbedding | 47
3 | prescalers | ModuleDict | 96
4 | static_variable_selection | VariableSelectionNetwork | 1.8 K
5 | encoder_variable_selection | VariableSelectionNetwork | 1.9 K
6 | decoder_variable_selection | VariableSelectionNetwork | 1.3 K
7 | static_context_variable_selection | GatedResidualNetwork | 1.1 K
8 | static_context_initial_hidden_lstm | GatedResidualNetwork | 1.1 K
9 | static_context_initial_cell_lstm | GatedResidualNetwork | 1.1 K
10 | static_context_enrichment | GatedResidualNetwork | 1.1 K
11 | lstm_encoder | LSTM | 2.2 K
12 | lstm_decoder | LSTM | 2.2 K
13 | post_lstm_gate_encoder | GatedLinearUnit | 544
14 | post_lstm_add_norm_encoder | AddNorm | 32
15 | static_enrichment | GatedResidualNetwork | 1.4 K
16 | multihead_attn | InterpretableMultiHeadAttention | 676
17 | post_attn_gate_norm | GateAddNorm | 576
18 | pos_wise_ff | GatedResidualNetwork | 1.1 K
19 | pre_output_gate_norm | GateAddNorm | 576
20 | output_layer | Linear | 119
----------------------------------------------------------------------------------------
18.9 K Trainable params
0 Non-trainable params
18.9 K Total params
0.075 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 2.0min remaining: 0.0s
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
----------------------------------------------------------------------------------------
0 | loss | QuantileLoss | 0
1 | logging_metrics | ModuleList | 0
2 | input_embeddings | MultiEmbedding | 47
3 | prescalers | ModuleDict | 96
4 | static_variable_selection | VariableSelectionNetwork | 1.8 K
5 | encoder_variable_selection | VariableSelectionNetwork | 1.9 K
6 | decoder_variable_selection | VariableSelectionNetwork | 1.3 K
7 | static_context_variable_selection | GatedResidualNetwork | 1.1 K
8 | static_context_initial_hidden_lstm | GatedResidualNetwork | 1.1 K
9 | static_context_initial_cell_lstm | GatedResidualNetwork | 1.1 K
10 | static_context_enrichment | GatedResidualNetwork | 1.1 K
11 | lstm_encoder | LSTM | 2.2 K
12 | lstm_decoder | LSTM | 2.2 K
13 | post_lstm_gate_encoder | GatedLinearUnit | 544
14 | post_lstm_add_norm_encoder | AddNorm | 32
15 | static_enrichment | GatedResidualNetwork | 1.4 K
16 | multihead_attn | InterpretableMultiHeadAttention | 676
17 | post_attn_gate_norm | GateAddNorm | 576
18 | pos_wise_ff | GatedResidualNetwork | 1.1 K
19 | pre_output_gate_norm | GateAddNorm | 576
20 | output_layer | Linear | 119
----------------------------------------------------------------------------------------
18.9 K Trainable params
0 Non-trainable params
18.9 K Total params
0.075 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 4.2min remaining: 0.0s
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
----------------------------------------------------------------------------------------
0 | loss | QuantileLoss | 0
1 | logging_metrics | ModuleList | 0
2 | input_embeddings | MultiEmbedding | 47
3 | prescalers | ModuleDict | 96
4 | static_variable_selection | VariableSelectionNetwork | 1.8 K
5 | encoder_variable_selection | VariableSelectionNetwork | 1.9 K
6 | decoder_variable_selection | VariableSelectionNetwork | 1.3 K
7 | static_context_variable_selection | GatedResidualNetwork | 1.1 K
8 | static_context_initial_hidden_lstm | GatedResidualNetwork | 1.1 K
9 | static_context_initial_cell_lstm | GatedResidualNetwork | 1.1 K
10 | static_context_enrichment | GatedResidualNetwork | 1.1 K
11 | lstm_encoder | LSTM | 2.2 K
12 | lstm_decoder | LSTM | 2.2 K
13 | post_lstm_gate_encoder | GatedLinearUnit | 544
14 | post_lstm_add_norm_encoder | AddNorm | 32
15 | static_enrichment | GatedResidualNetwork | 1.4 K
16 | multihead_attn | InterpretableMultiHeadAttention | 676
17 | post_attn_gate_norm | GateAddNorm | 576
18 | pos_wise_ff | GatedResidualNetwork | 1.1 K
19 | pre_output_gate_norm | GateAddNorm | 576
20 | output_layer | Linear | 119
----------------------------------------------------------------------------------------
18.9 K Trainable params
0 Non-trainable params
18.9 K Total params
0.075 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 6.3min remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 6.3min finished
[17]:
metrics_tft
[17]:
| segment | SMAPE | MAPE | MAE | fold_number | |
|---|---|---|---|---|---|
| 1 | segment_a | 5.299614 | 5.360709 | 26.895150 | 0 |
| 1 | segment_a | 8.529496 | 8.275338 | 43.386976 | 1 |
| 1 | segment_a | 4.211704 | 4.061221 | 22.613626 | 2 |
| 0 | segment_b | 6.320653 | 6.111722 | 15.759892 | 0 |
| 0 | segment_b | 5.739079 | 5.496857 | 14.375443 | 1 |
| 0 | segment_b | 3.686370 | 3.800662 | 9.226279 | 2 |
| 2 | segment_c | 4.024918 | 3.973560 | 6.912822 | 0 |
| 2 | segment_c | 6.871641 | 6.599788 | 12.265241 | 1 |
| 2 | segment_c | 4.480460 | 4.373238 | 8.129543 | 2 |
| 3 | segment_d | 7.411609 | 7.225217 | 63.221671 | 0 |
| 3 | segment_d | 4.774683 | 4.724345 | 38.271014 | 1 |
| 3 | segment_d | 2.764979 | 2.699242 | 20.584342 | 2 |
[18]:
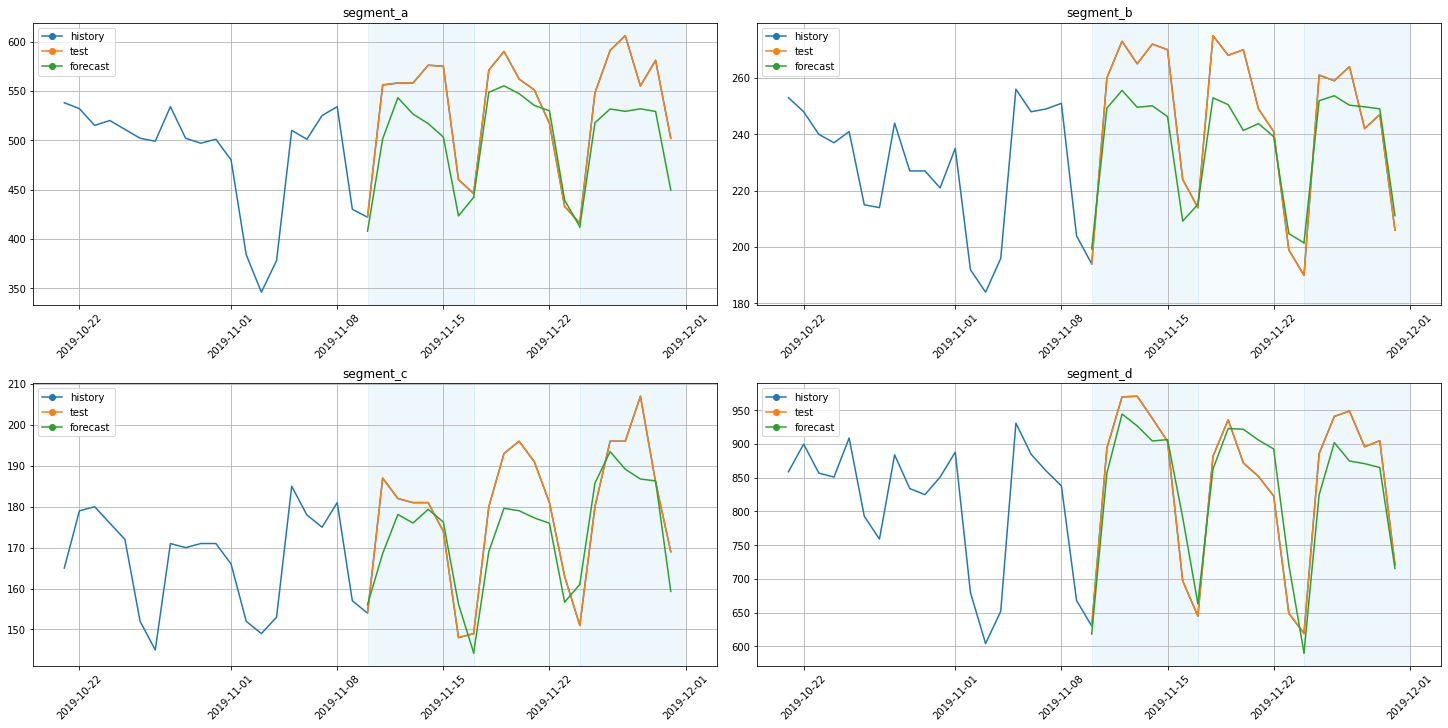
score = metrics_tft["SMAPE"].mean()
print(f"Average SMAPE for TFT: {score:.3f}")
Average SMAPE for TFT: 5.343
[19]:
plot_backtest(forecast_tft, ts, history_len=20)
3.3 Simple model¶
For comparison let’s train a much more simpler model.
[20]:
model_sma = SeasonalMovingAverageModel(window=5, seasonality=7)
linear_trend_transform = LinearTrendTransform(in_column="target")
pipeline_sma = Pipeline(model=model_sma, horizon=HORIZON, transforms=[linear_trend_transform])
[21]:
metrics_sma, forecast_sma, fold_info_sma = pipeline_sma.backtest(ts, metrics=metrics, n_folds=3, n_jobs=1)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 0.2s finished
[22]:
metrics_sma
[22]:
| segment | SMAPE | MAPE | MAE | fold_number | |
|---|---|---|---|---|---|
| 1 | segment_a | 6.343943 | 6.124296 | 33.196532 | 0 |
| 1 | segment_a | 5.346946 | 5.192455 | 27.938101 | 1 |
| 1 | segment_a | 7.510347 | 7.189999 | 40.028565 | 2 |
| 0 | segment_b | 7.178822 | 6.920176 | 17.818102 | 0 |
| 0 | segment_b | 5.672504 | 5.554555 | 13.719200 | 1 |
| 0 | segment_b | 3.327846 | 3.359712 | 7.680919 | 2 |
| 2 | segment_c | 6.430429 | 6.200580 | 10.877718 | 0 |
| 2 | segment_c | 5.947090 | 5.727531 | 10.701336 | 1 |
| 2 | segment_c | 6.186545 | 5.943679 | 11.359563 | 2 |
| 3 | segment_d | 4.707899 | 4.644170 | 39.918646 | 0 |
| 3 | segment_d | 5.403426 | 5.600978 | 43.047332 | 1 |
| 3 | segment_d | 2.505279 | 2.543719 | 19.347565 | 2 |
[23]:
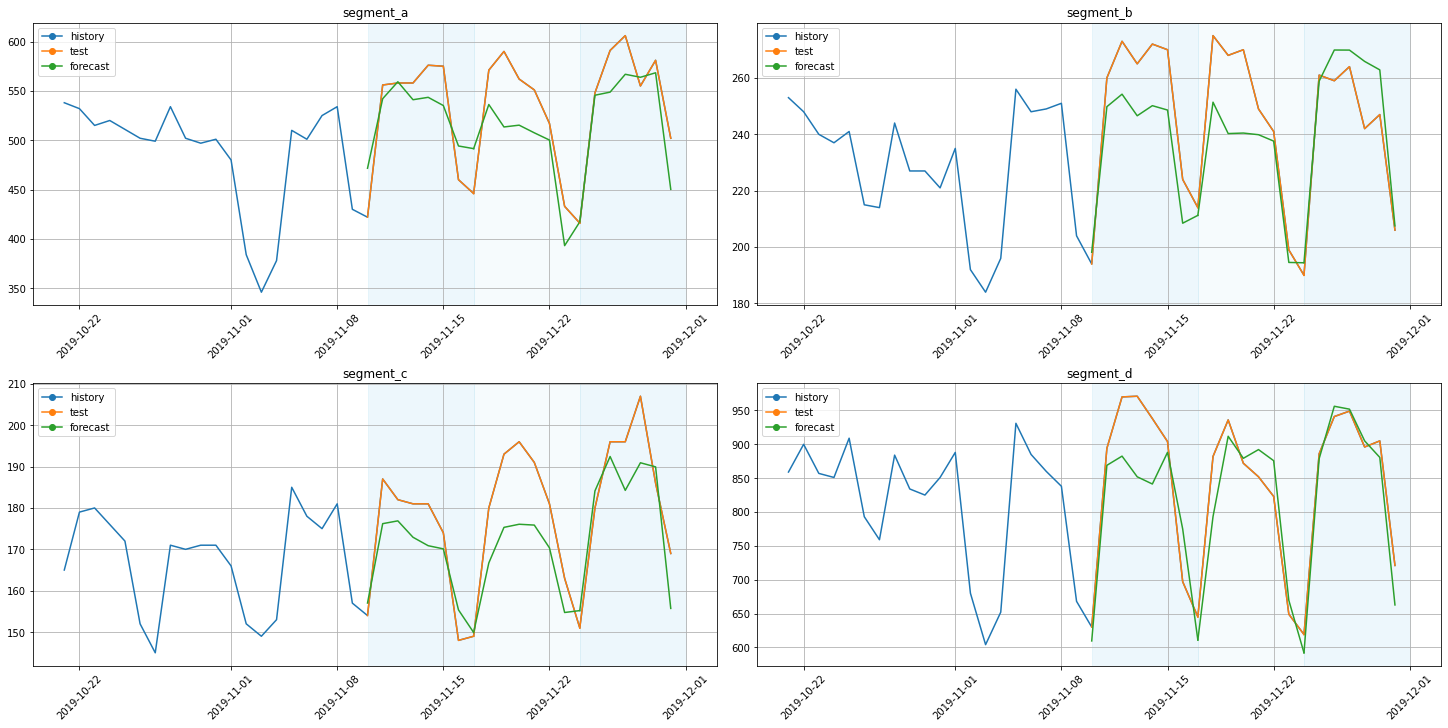
score = metrics_sma["SMAPE"].mean()
print(f"Average SMAPE for Seasonal MA: {score:.3f}")
Average SMAPE for Seasonal MA: 5.547
[24]:
plot_backtest(forecast_sma, ts, history_len=20)
As we can see, neural networks are a bit better in this particular case.
4. Etna native deep models¶
PytorchForecastingTransform now.We’ll use RNN model based on LSTM cell
[25]:
from etna.models.nn import RNNModel
from etna.transforms import StandardScalerTransform
[26]:
model_rnn = RNNModel(
decoder_length=HORIZON,
encoder_length=2 * HORIZON,
input_size=11,
trainer_params={"max_epochs": 5},
lr=1e-3,
)
pipeline_rnn = Pipeline(
model=model_rnn,
horizon=HORIZON,
transforms=[StandardScalerTransform(in_column="target"), transform_lag],
)
[27]:
metrics_rnn, forecast_rnn, fold_info_rnn = pipeline_rnn.backtest(ts, metrics=metrics, n_folds=3, n_jobs=1)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
---------------------------------------
0 | loss | MSELoss | 0
1 | layer | LSTM | 4.0 K
2 | projection | Linear | 17
---------------------------------------
4.0 K Trainable params
0 Non-trainable params
4.0 K Total params
0.016 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 2.7s remaining: 0.0s
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
---------------------------------------
0 | loss | MSELoss | 0
1 | layer | LSTM | 4.0 K
2 | projection | Linear | 17
---------------------------------------
4.0 K Trainable params
0 Non-trainable params
4.0 K Total params
0.016 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 5.4s remaining: 0.0s
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
---------------------------------------
0 | loss | MSELoss | 0
1 | layer | LSTM | 4.0 K
2 | projection | Linear | 17
---------------------------------------
4.0 K Trainable params
0 Non-trainable params
4.0 K Total params
0.016 Total estimated model params size (MB)
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 8.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 8.2s finished
[28]:
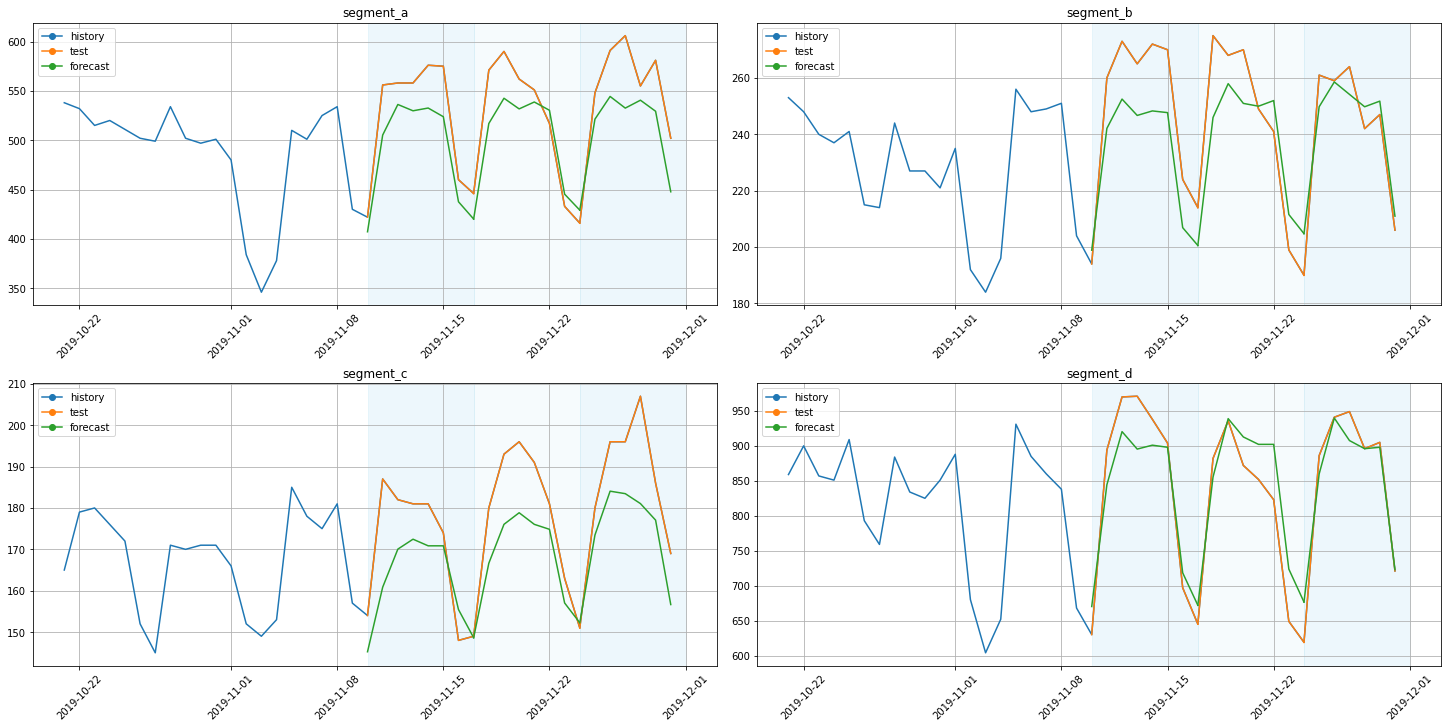
score = metrics_rnn["SMAPE"].mean()
print(f"Average SMAPE for LSTM: {score:.3f}")
Average SMAPE for LSTM: 6.402
[29]:
plot_backtest(forecast_rnn, ts, history_len=20)